Hyper parameter tuning
In this section we provide experiments to tune the default solution of the default Predator-Prey-Grass environment towards anmore efficient solution. Training a default environment satifactory (meaning that the simulation runs until truncation of 1000 evaluaion steps), takes about 9 hours of compute time on a 32 CPU/1 GPU machine. The goal of our tuning experiments is to reduce compute time while remaining the same rewards (ie. reproduction) structure. The default PPO configuration is shown in Display 1.
"config_ppo": {
"max_iters": 1000,
"lr": 0.0003,
"gamma": 0.99,
"lambda_": 1.0,
"train_batch_size_per_learner": 1024,
"minibatch_size": 128,
"num_epochs": 30,
"entropy_coeff": 0.0,
"vf_loss_coeff": 1.0,
"clip_param": 0.3,
"num_learners": 1,
"num_env_runners": 8,
"num_envs_per_env_runner": 3,
"num_gpus_per_learner": 1,
"num_cpus_for_main_process": 4,
"num_cpus_per_env_runner": 3,
"sample_timeout_s": 600,
"rollout_fragment_length": "auto",
"kl_coeff": 0.2,
"kl_target": 0.01
}
This configuration shows all explicitly defined hyperparameters. All other hyperparameters are implicitly defined by the Ray RLlib defaults. This setup generates the reward results for a typical predator and a typical prey are shown in display 1.The total tarining involved 1,000 iterations, which took 9.7 hours (see Display 3).
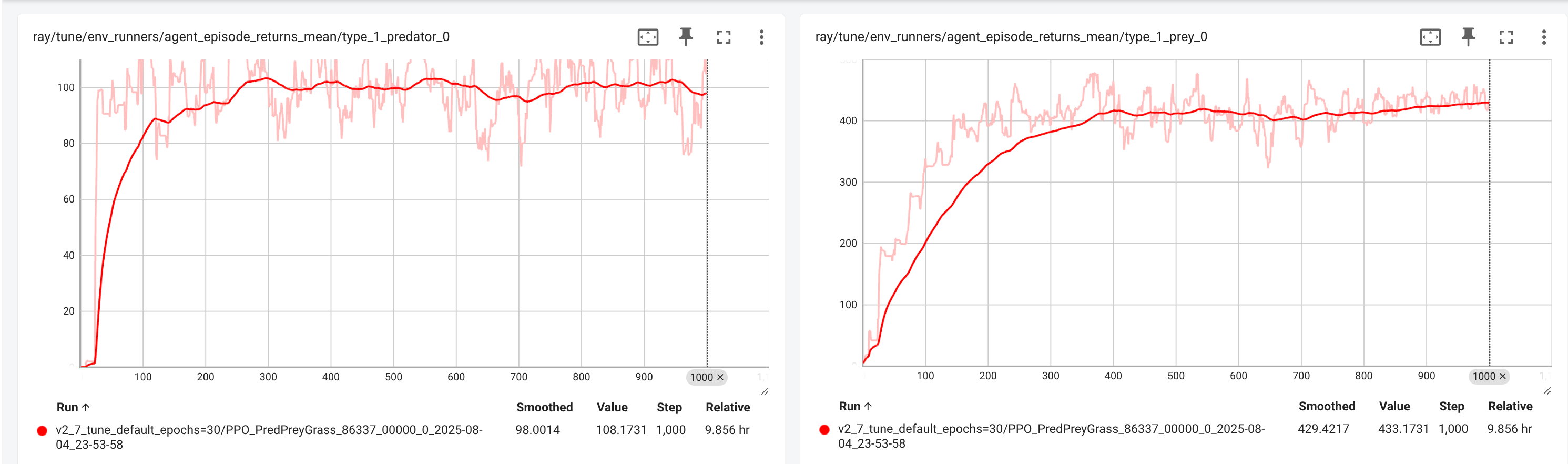
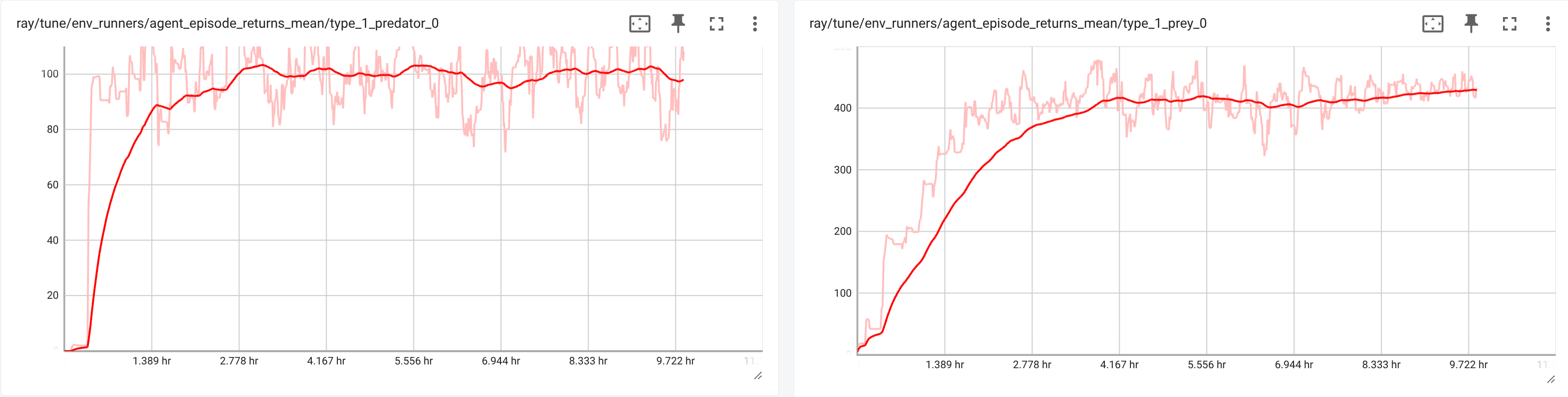
Trial and error changing of the deafult PPO configuration revealed that the wall time was especially impacted by the number of epochs(num_epochs) in the configuration, which is 30 in the default configuration. Therefore we have conducted a parameter variation experiment with respect to this hyperparameter.