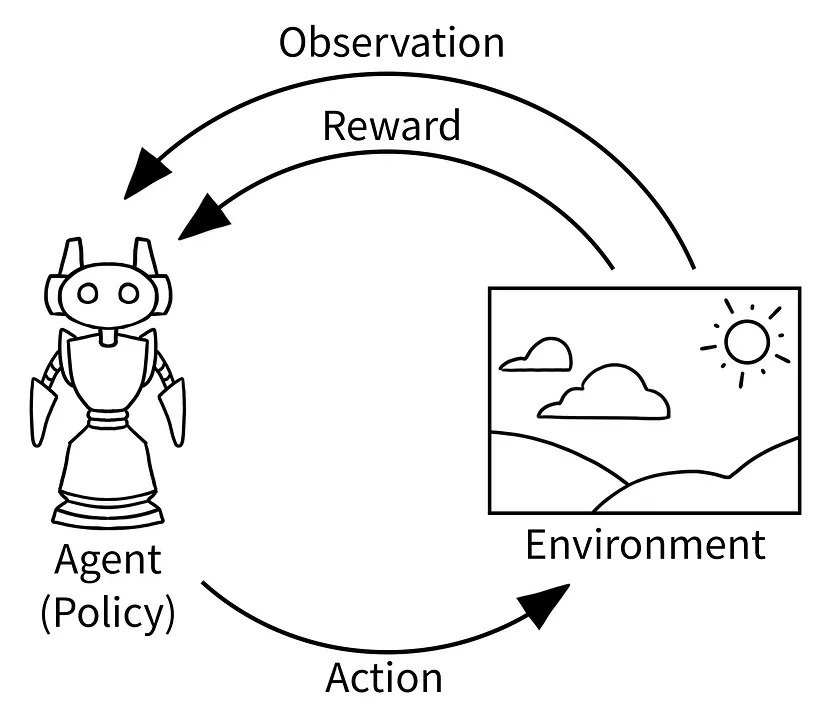
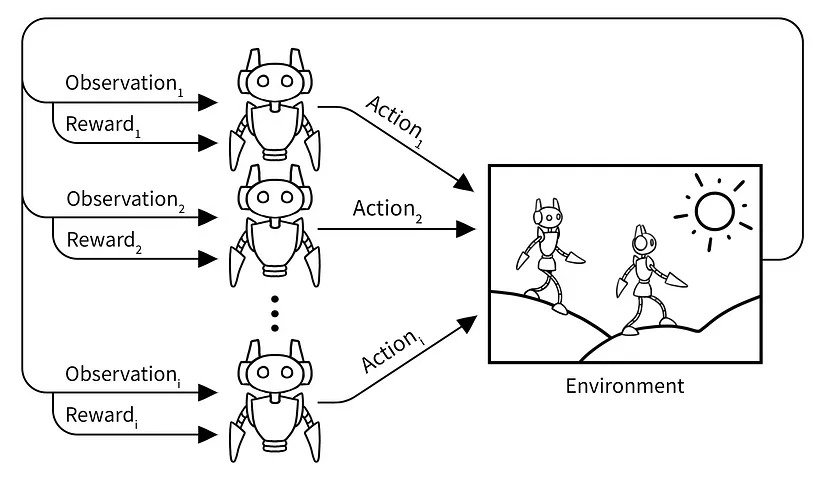
Multi Agent Reinforcement Learning
Multi Agent Reinforcement Learning (MARL) as a tool for modeling human behavior
Multi Agent Reinforcement Learning (MARL) is fundamentally different from other traditional Machine Learning (ML) paradigms. The main three traditional paradigms in ML are: Supervized Learning, Unsupervized Learning and Reinforcement Learning. Most applications in ML or (more general) Artificial Intelligence (AI), like for instance Large Language Models (LLM) are largely derived from (a mixture) of those paradigms.
RL in a way distinguishes itself from Supervized and Unsupervized Learning, which is in a certain way nothing more than an advanced form of curve fitting of prefabriced data. RL, on the other hand, learns through sequential interaction with an environment, driven by rewards or penalties, rather than from a static dataset. In Display 2 are highlights some distinctions between the different approaches.
| Aspect | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Feedback signal | Correct output labels | No labels | Rewards from environment |
| Learning type | Passive (from examples) | Passive (find structure) | Active (trial-and-error interaction) |
| Goal | Minimize error | Find structure or compression | Maximize reward over time |
| Example task | Image classification | Customer segmentation | Game playing, robot navigation |
| Data type | Labeled | Unlabeled | Dynamic experience |
In our endevour of modeling human behavior we have decided to follow the descriptive agenda of Multi Agent Reinforcement Learning. The descriptive agenda uses MARL to study the behaviors of natural agents, such as humans and animals, when learning in a population.This agenda typically begins by proposing a certain MARL algorithm which is designed to mimic how humans or animals adapt their actions based on past interactions. Methods from social sciences and behavioral economics can be used to test how closely a MARL algorithm matches the behavior of a natural agent, such as via controlled experimentation in a laboratory setting. This is then followed by analyzing whether a population of such natural agents converges to a certain kind of equilibrium solution if all agents use the proposed MARL algorithm.
To choose for this discriptibve approach is an important but inevatably also an ambiguous choice. We try to find which (minimal) fundamental features humans need to posses in order to display emergent behaviors like cooperationa and competition. However, almost by definition we need to deploy a priori subkective restrictions and opportunities in the simulation, because othwerwise exploring emergent human behavior similar to the current human behavior observed in the real world is too much of a long shot. Evolution and learning is subject to too much randomness to come up with a simple singular evolutionary simulation. It is in our view very unlikely if evolution started all over again from the big bang, we would come up with the same outcome. Perhaps dinosaurs ruled the world after all, instead of humans, or whatever. Therefore, it is pointless (and most likely also impossible) to simulate and apply reinforcement learning of human behavior by starting from scratch because it will lead very likely to absurd varying outcomes of human life and human behavior. (if humans were to appear at all). Therefore it is inevitable and necessary to a priori endow characteristics of humans into simulation models, making modeling of course subjective unfortunately. It is nevertheless the challenge to identify uuniversal emergent behavior out of human group dynamics with multi agent reinforcement learning, with making as few presumptions as possible.
The increasing comlexity of Multi Agent Reinforcement Learning
Building and observing interactions between artificial agents could help us to gain better understanding about human behavior. MARL can be sub divided into three categories:
- Competitive setting
- Cooperative setting
- Mixed setting (both competitive and cooperative)
Multi agent reinforcement learning (MARL) is an interesting avenue to investigate human behavior and emergent group phenomena. Although recent years have brought advances in this field, significant results are still scarce. Single Agent Reinforcement Learnings has already established wide recognition and practical implementations. However, Multi Agent Reinforcement Learning is still in its infancy. For instance, because of the extra complexity, multi-goal behavior and the fact that learning agents for other agents are part of an (anticpating) environment. Especially the latter is able to induce a continuos needed changing adaptation between agents. Consequently, the environement de facto anticipates the actions of agents, and a continuous viscious cyce of anticipating agents can emerge. This can be described with autocurricula; a reinforcement learning concept that is a typical characteristic in multi agent learning. As agents improve their performance, they change their environment; this change in the environment affects themselves and the other agents. The feedback loop results in several distinct phases of learning, each depending on the previous one. The stacked layers of learning are called an autocurriculum. Autocurricula are especially apparent in adversarial settings, where each group of agents is racing to counter the current strategy of the opposing group.